In the previous blog post on this topic I wrote about my work as a lead engineer on a small team taking part in the FINOS 2024 Tech Sprint - a multi-week hackathon centered around the TraderX project, which is essentially an example system (think ’Pet Store’) that is intended purely for educational and training purposes. TraderX was initially developed by Morgan Stanley.
In this follow-up post I will share some thoughts about XTDB (a ‘bitemporal’ database created by JUXT) and discuss a few potential future directions for the codebase. As a recap, here is a short video we put together that provides an overview of the system and some of the changes we made:
First Impressions
This was my first time using XTDB so I had some learning to do. Being a SQL database, most things about XTDB felt quite familiar but it still takes a little time to get used to the temporal syntax (at least you only have to learn it once!).
After studying the existing TraderX data model and reading the project brief, my instinctive reaction was to start adding dedicated columns to the application’s schema for handling various application and auditing timestamps like traded_at and updated_at - but what a pleasant surprise it was to find out there’s little need for many of these kinds of columns in XTDB - such timestamping is already ubiquitous and all handled under the covers.
The biggest surprise, however, was that because of this built-in functionality, compared to using a traditional SQL database for recording changes and keeping old versions around, how you interact with an XTDB database remains intuitive - at least until you need to retrieve the historical data or introduce ‘retroactive’ updates (e.g. when you discover some past data was incorrect and need to correct it, or when you want to backfill some missing data). Essentially, you are able to use plain INSERT, UPDATE and DELETE statements to modify data as normal, yet you are left with a fully auditable history of all changes across all records and can easily query past states.
Wait - what? History? Yes! You get all the change history for free! Not just what changed when, but a fine-grained ability to query the myriad historical database states exactly as they looked previously. For example, UPDATE statements in XTDB don’t actually overwrite old values - instead they create new entries that are carefully tracked across two time lines - ‘valid time’ (otherwise known as ‘application time’) and system time (what you can think of as wall-clock time).
The way the XTDB team have extended the ‘normal’ update-in-place semantics of SQL is straightforward and feels reassuring to work with. You can insert data, modify it, see the current state based on those changes (i.e. historical states are filtered away by default). However, you can always go back and see how the data looked previously, and concurrent users can work with stable views of historical data (e.g. for reporting) while new transactions occur. All of this, combined with the rich flexibility of SQL is an attractive proposition.
Integrating Sliders
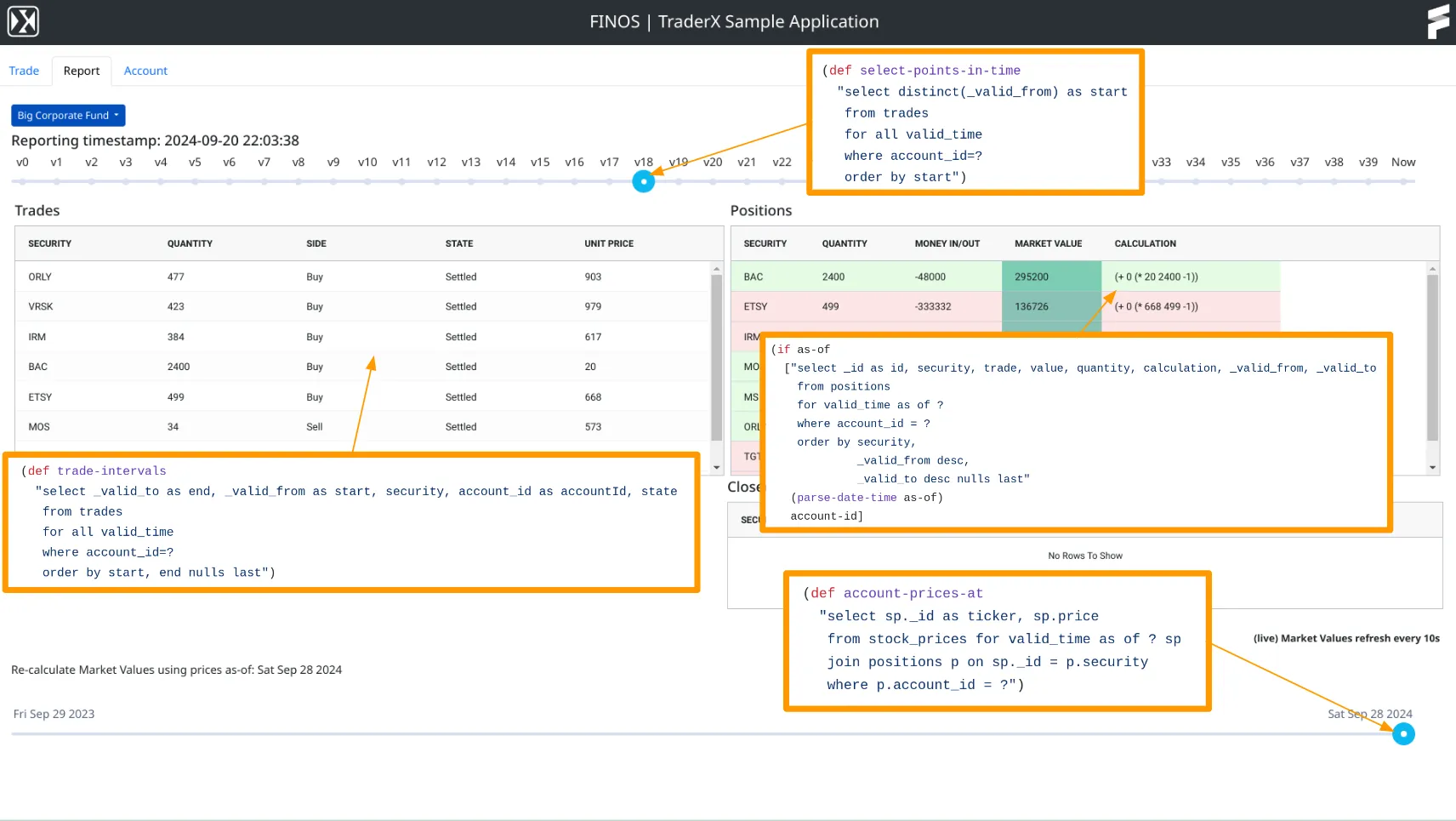
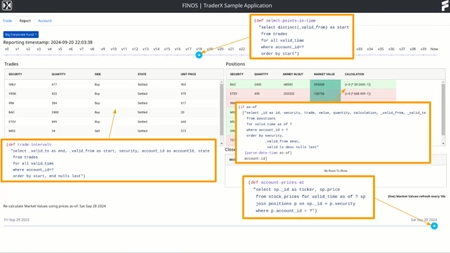
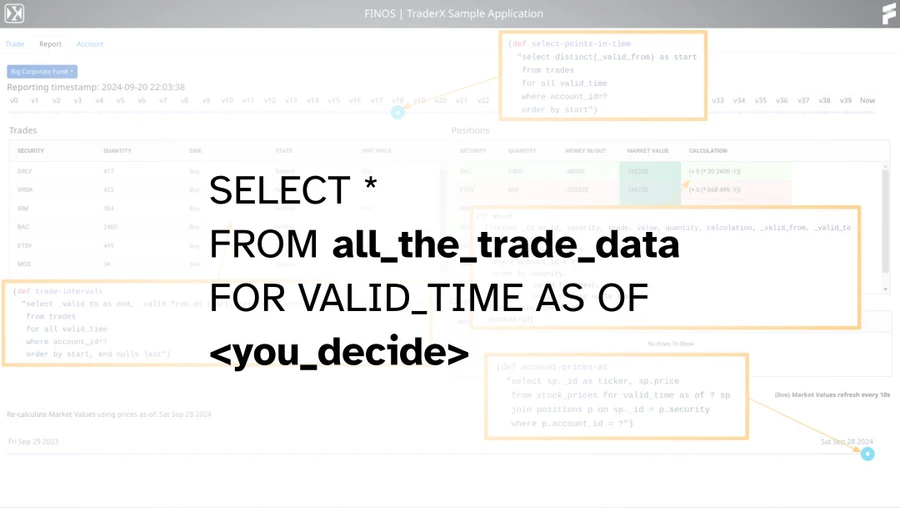
Adding temporal ‘sliders’ to the TraderX UI was an easy way to expose XTDB’s time-travel capabilities. This approach makes it efficient for users of the various blotters and dashboards to quickly observe and scrub through the changing data, compared to alternatives like having to click on some calendar widget to navigate through the history. It’s a great way to understand the value that the bitemporal model can bring: just imagine any existing application with a time slider and how useful that could be for the end user - especially in domains where the end user is making important decisions based on the changing data, and you later want (or need!) to be able to reconstruct the full context behind the decision.
Implementing this change required fetching data from multiple joined tables ‘as of’ a certain point in time. This involves a small amount of ceremony, particularly if you want to be able to control specific valid time or system time views for each table independently. However, if you don’t need such detailed control, you can set the as-of time for the entire query quite easily using syntax like SETTING DEFAULT VALID_TIME AS OF DATE '2020-01-01' ...
It also took me a couple of iterations to get timeline markers displayed correctly for the ‘event’ slider, which consolidates the history from all known versions of trades - and therefore corresponds to various moments in time when portfolio positions change.
Initially, I naively queried for a collection of time periods, using _valid_from as the period start and _valid_to as the period end for all trades in ascending order. However, this approach was flawed because the periods were interleaved across the unrelated trades. Instead, what I ended up creating was a slider where all markers are purely _valid_from values across all trades (and without restrictions on _valid_to). This provided the clear and accurate trade history timeline I was looking for, to represent lifecycle events from creation to settlement.
In addition to the main blotter slider, I also added a price slider. This was much simpler - essentially, a basic view of price ‘as of’ a given day, using regular daily steps. The single blotter SQL query then seamlessly joins across these two underlying table sources using their respective as-of timestamps.
Takeaway Opinions
Having worked on several applications that incorporate reporting requirements, I can confidently say that XTDB offers significant advantages over traditional SQL databases.
Automatic bitemporal versioning unlocks powerful reporting capabilities - not only over past changes, but also for speculative analysis. For example:
- “What would my account PnL look like with prices from a given day in the past?”
- “How much could I have gained/lost if I had bought stock X on date Y?”
XTDB makes this possible without requiring planning ahead or implementing distinct versioning requirements in each part of the schema.
A first-class history close to hand is a game changer for application development - a whole range of time-related complexities are taken care of by the bitemporal model, and XTDB makes working with bitemporal data very easy. You could compare this shift in thinking to how database-managed transactions replaced manual transaction handling in application code—simplifying development considerably. There is a little bit to learn about in order to start using SQL:2011’s temporal operators - but this is really nothing compared to benefits you get from just using it.
XTDB provides bitemporal storage with virtually no barrier to entry - DML SQL statements (INSERT, UPDATE, DELETE) behave as expected, seamlessly inserting new rows instead of modifying existing data, but retrieving historical data when you need it is a breeze using SQL:2011 operations (e.g. ‘FROM my_table FOR VALID TIME FROM … TO …’ to fetch past data). The only limitation felt in this project was that XTDB doesn’t yet fully work with JPA-style persistence, due to minor differences with real PostgreSQL, but working with plain SQL or simpler abstractions (e.g. jOOQ) is my preference anyway.
No more need for bespoke audit tables or manually adding basic timestamped fields like ‘updated_at’ - history is transparently preserved across both system time and valid time dimensions. There is even a built-in transaction log table that reveals the full history of transaction events and their timestamps.
XTDB drastically reduces complexity that is otherwise introduced by hand-rolled reporting solutions. These typically emerge as post-production requirements (often driven by regulatory, auditing, or legal needs). With XTDB, developers can focus on building unique, competitive features instead of implementing custom versioning mechanisms that, while necessary, do not add direct value to the end user.
Ideas for the future
If XTDB adds full support for JPA-style persistence, then XTDB could fully replace the use of the H2 database within the TraderX repo, without requiring any code changes. In a future Tech Sprint we may consider attempting this, and also adding additional reporting functionality (e.g. predicted vs. actual comparisons).
It would also be interesting to expand TraderX with semi-structured data (e.g. email chains, or risk data) to demonstrate how XTDB is well-suited for handling evolving schemas over time whilst also providing ACID transactions - and without resorting to JSON serializations.
The XTDB team are looking for Design Partners
JUXT is currently collaborating with several Design Partners using XTDB who help us identify and implement missing features - we cannot responsibly take on too many partners (as we do need to support those features!), but if you feel like XTDB could be the right fit for your problem, please do get in touch: hello@xtdb.com