

In order to prevent xt-play from having downtime due to traffic spikes, I converted the backend to run on AWS Lambda (previously it was running on AWS ECS with Fargate). While doing so I had a bunch of trouble so I wanted to write down what worked for me. Hopefully it can help you out too!
A quick note on my constraints: xt-play works by spinning up a fresh XTDB
node for each request. This meant that I needed the lambda to run on the plain
old JVM. No ClojureScript for me! As it happened this was quite quick to get
started with (once I figured out what functions to put where).
Creating our jar
Let’s start by making a sample project:
$ mkdir -p sample-lambda/src/
$ cd sample-lambdaNext let’s add our dependencies, I’ll be using deps.edn but feel free to use
whatever build tooling you like:
{:paths ["src"]
:deps {org.clojure/clojure {:mvn/version "1.11.1"}
com.amazonaws/aws-lambda-java-core {:mvn/version "1.2.3"}}
:aliases
{:build {:extra-deps {io.github.clojure/tools.build {:git/tag "v0.8.4" :git/sha "8c3cd69"}}
:ns-default build}}}The important one is aws-lambda-java-core
which provides the interface we need to implement in our src/lambda.clj:
(ns lambda
(:gen-class
:implements [com.amazonaws.services.lambda.runtime.RequestStreamHandler]))
(defn -handleRequest [_ is os _context]
(let [input (slurp is)]
(if (re-find #"error" input)
(throw (ex-info "test" {:my "error"}))
(spit os "test"))))Here I’m reading the input as a string using slurp, but elsewhere I’ve had
success reading JSON using cheshire’s
parse-stream and muuntaja’s decode.
The Lambda Java runtime
requires a jar so let’s build one with tools.build:
(ns build
(:require [clojure.tools.build.api :as b]))
(def lib 'my/lambda)
(def version (format "0.1.%s" (b/git-count-revs nil)))
(def class-dir "target/classes")
(def basis (delay (b/create-basis {:project "deps.edn"})))
(def uber-file (format "target/%s-%s-standalone.jar" (name lib) version))
(defn clean [_]
(b/delete {:path "target"}))
(defn uber [_]
(b/copy-dir {:src-dirs ["src" "resources"]
:target-dir class-dir})
(b/compile-clj {:basis @basis
:src-dirs ["src"]
:class-dir class-dir})
(b/uber {:class-dir class-dir
:uber-file uber-file
:basis @basis}))Now we can build a jar with clj -T:build uber:
$ clj -T:build uber
$ ls target
classes
lambda-0.1.1-standalone.jarFinally with our jar in hand it’s as easy as following these instructions to create your new Lambda!
All of this code can be found in this repo.
Bonus: A full-stack application in a lambda
For xt-play I wanted the deployment to be as simple as possible, and what could
be simpler than a webserver serving a static frontend with some api routes?
I’ve got a demo repo here,
or you can look at the (much messier) xt-play source.
As an overview, I:
- Moved the clojure source to
src/clj - Added
reititandmuuntajaas dependencies - Added
resourcesto the paths (took me too long to figure out!) - Created some conversion functions between what function URL’s want and what
ringwants (this post was super helpful!) - Added a
src/clj/handler.cljnamespace with myreititroutes - Created a
shadow-cljsproject that builds toresources/public/js/w/ associatedpackage.json - Told
build.cljto build myshadow-cljsproject when a jar is built
Phew, but with that we’re done!
Just upload your new jar and create a function url
then any requests to it will go through to the reitit handler.
As a bonus bonus: you can even develop against a local webserver using user/go!.
A note on performance
Performance wise, you’ll probably find the above fine for a lot of use cases, but if you’re finding cold start times too high there are some options:
SnapStart is a completely free way to improve your cold starts, all you need to do is configure it and publish a version and they’ll auto-magically be faster!
Another option (that works with SnapStart!) is to increase the CPU power of the Lambda which is done by increasing the memory. Even though it’s more expensive per GB-second, because having more CPU means that your Lambda can execute quicker, the cost can even out. There’s an excellent tool called AWS Lambda Power Tuning which can help automate the process of selecting the right amount of memory.
Here’s the output for xt-play’s cold starts:
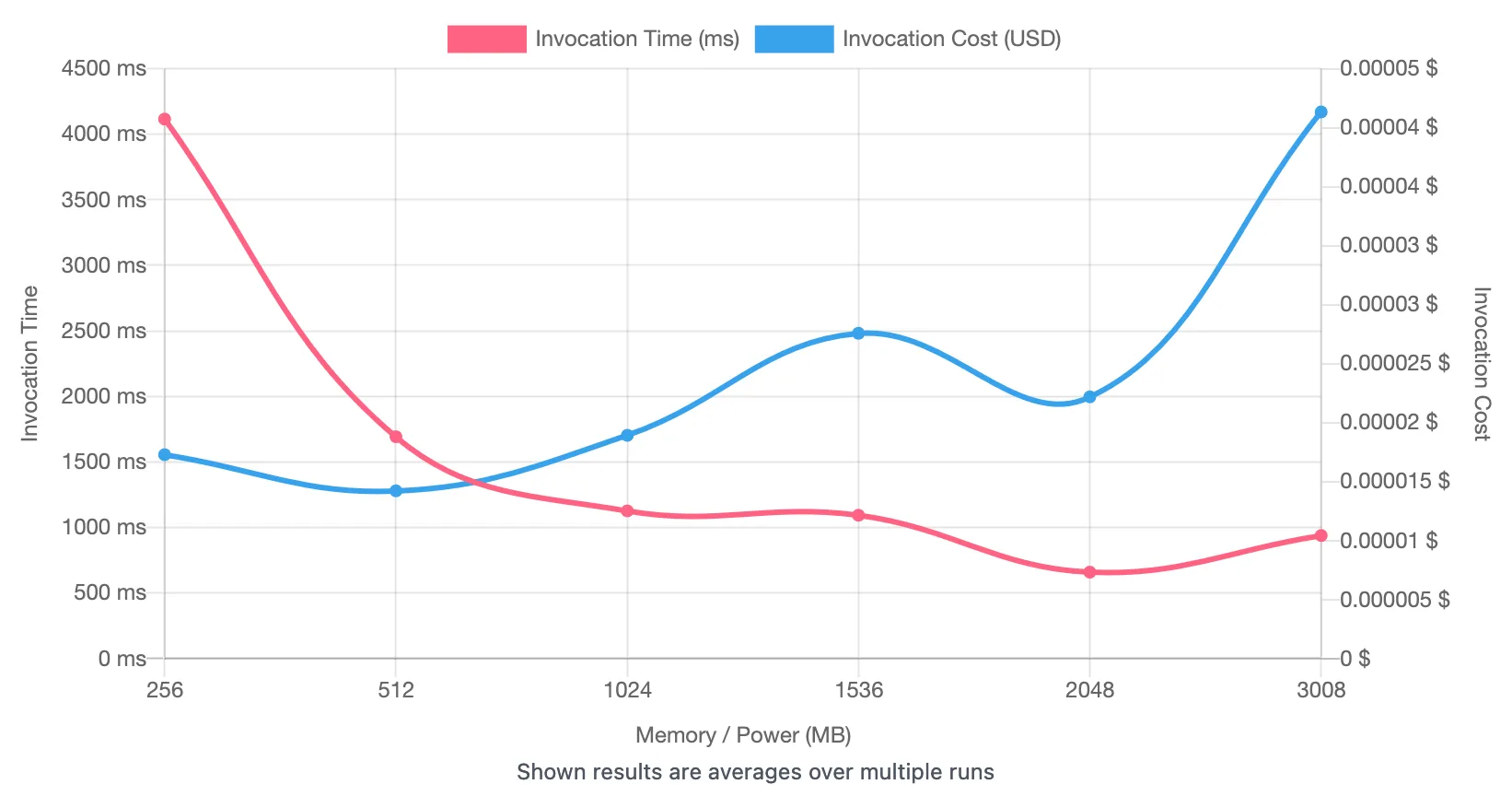
It’s slightly inaccurate because each configuration is only executed once, but there’s a PR to do this properly which looks like it’ll be done soon.
And here’s the output for warm starts (I set it to 100 invocations each):
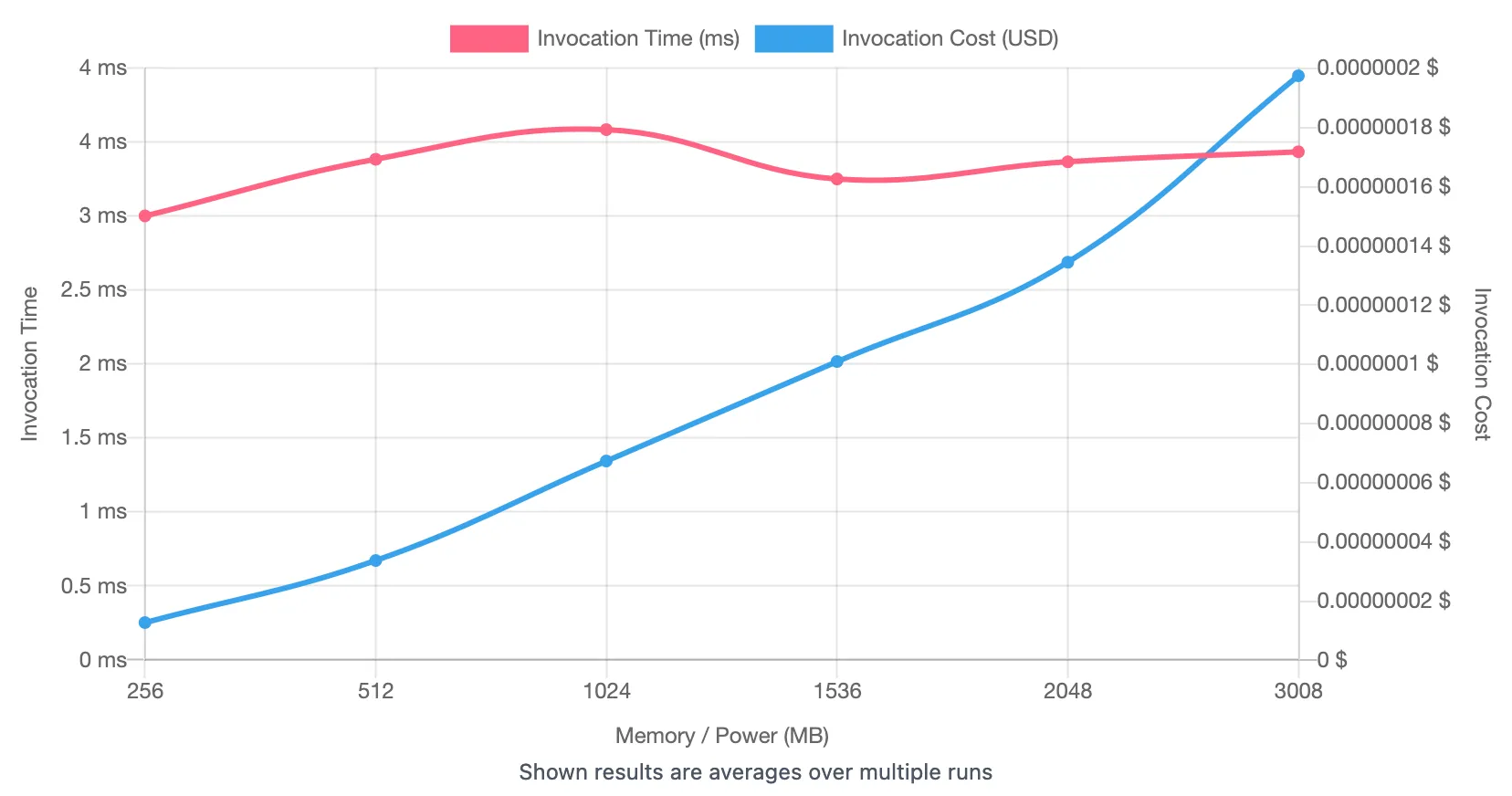
So it looks like (for xt-play) more memory/CPU won’t give us more performance once the Lambda’s warm, but it will improve our cold start time.
I found this was enough for xt-play, but AWS has some other recommendations that might be useful. And if you don’t require a JVM you can always:
Happy hacking!




