

Crux is now XTDB
September 2021 Update: Crux has recently been renamed XTDB. This post
still refers to XTDB as “Crux” but you will find newer versions of the
artifacts discussed under the new com.xtdb Maven GroupId
([com.xtdb/xtdb-core "1.19.0"] for example) instead of the pro.juxt
GroupId.
The official home for XTDB is now https://xtdb.com.
Most of us might have coded up the humble database column
updated_date, at some point or another, giving us a feeling that data
and time are nearly always intrinsically linked in our database designs.
Along with updated_date, we may also find ourselves needing
created_date, to preserve an immutable record of the row’s origin.
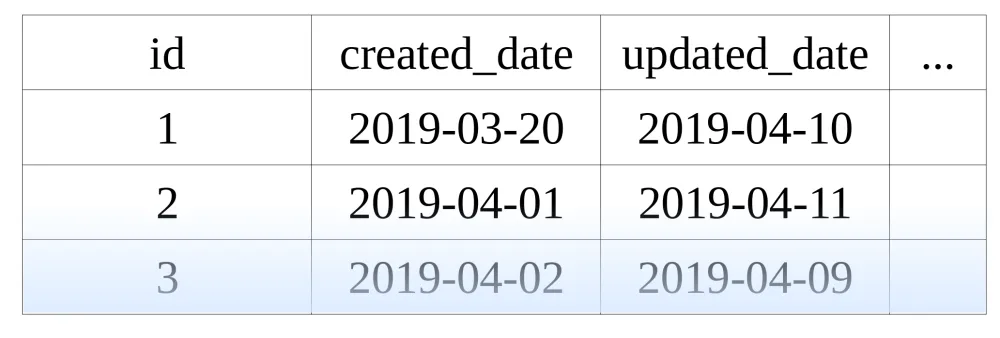
Sometimes we will need to keep the historical versions of entities around also, either for audit reasons or to serve business requirements where historical data can inform future decisions.
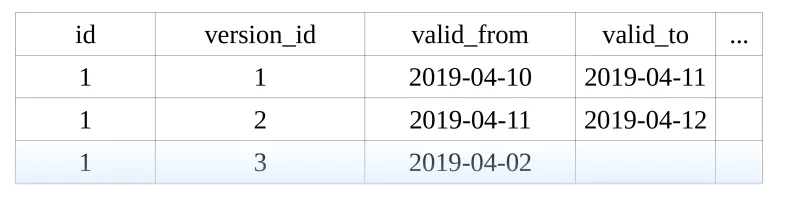
In table above we maintain versions of entities by using valid_from
and valid_to. This allows us to navigate to a particular version of an
entity that was live at a given time.
This approach is pragmatic and has benefits, but it adds complexity to the database design. It also relies on updating database rows to set the date columns, which hampers future efforts to work with the database as an immutable store.
Temporal Databases
Temporal databases aim to make our programming lives easier around time,
by baking time itself into the engine. One major feature of temporal
databases is the ability to query the database as of a particular
point in time.
The SQL:2011 specification gives syntax for this:
SELECT... AS OF SYSTEM TIMETo facilitate this, the database itself maintains a transaction time
(aka system time) for each transaction, and it is always increasing so
that the past is immutable. This allows you to query the database at any
point on the transaction time axis, to see what the database looked
like in a given point in history.
The transaction time of a database fact is the time when the fact is current in the database and may be retrieved
— Glossary of Temporal Database Concepts
transaction time is the time at which the database sees incoming data.
This gives an inherent audit log, maintaining an immutable history of
database transactions.
Temporal databases may also offer the ability to get the history of entities, or to query using temporal predicates (i.e. find me all cases when a field was changed in a certain time span). They may also offer support for time-series investigations to help analyze out trends and to make predictions.
An example use-case of where as of may be useful is in financial
services, where regulatory regimes demand that financial trades can be
reconstructed to show how they were priced, based on the available
market data at the time.
To develop this kind of trade-reconstruction functionality without
temporal functionality such as as of, is surprisingly difficult to do.
To get around this, data is often copied and put aside, with an
increased operations management overhead.
If our databases have temporal functionality then we can simply query
the database as of the trade creation time, to discover why the trade
was priced the way it was.
Whose time is it anyway?
If your database is the only database in the mix and is therefore the
singular source of truth, then transaction time could be all that
matters.
What happens however, if your database is fed from some upstream source, which is a common occurrence in large enterprises?
In systems with substantial data, the database being queried against is
often a materialised view formed off the back of an upstream event-log,
and it’s the time when the data entered the event-log that we care most
about. It’s this time axis that we may want to query against using
techniques such as as of, rather than transaction time.
This additional timestamp field - originating upstream - could represent the real truth of when a fact was made a reality, not just when it was transacted.
Bitemporality is about the introduction of a second time axis, called
valid time.
The valid time of a fact is the time when the fact is true in the modelled reality
— Glossary of Temporal Database Concepts
Valid Time
With bitemporality, the powerful things you can do in a temporal
database against a single time axis of transaction time, you can do
against two axes of time: transaction time and valid time.
In the case of a database being fed from some upstream source, the
immediate database would still own and govern transaction time, but
valid time would be passed to it in each transaction.
This would allow programmers to perform temporal queries such as as of
against valid time, which is a more typical business use-case.
Immutability of the database will still be preserved, because
transaction time is always increasing and you can’t update or erase
the transaction time past.
When performing temporal queries, programmers will be able to query
as of a bitemporal co-ordinate, i.e. to be shown the state of the
world at a point in valid time, but also at a point in
transaction time past. This allows for query consistency, factoring in
both time axes.
Updating the Past
valid time has a fundamental difference to transaction time, in that
you can insert into the past.
In the messy world of enterprise IT, data is frequently moved about wholesale, be it data-centre migrations to the cloud, compacting, backups, ETL jobs to provide materialised views… data is nearly always on the move.
There may be times when we want to do bulk-loads into the past, and if we’re reliant purely on a single monotonically increasing time-axis, then this is going to be a challenge, especially if we want to preserve transaction time as something meaningful to query against. Add in the potential need for parallel data-writing to speed up ingestion, then the problem is exacerbated.
valid time is more flexible. You can insert into the past of
valid time, and therefore it doesn’t matter in which order
transactions are committed.
This also helps for global data topologies; if your database is being fed transactions from upstream sources, it might be inescapable that transactions will occasionally arrive out of order.
valid time also opens up the possibility of sharding for horizontal
scaling, whereby different data-stores might have differing
transaction times for when facts were transacted, but then you could
achieve query consistency using valid time.
N-Temporality?
Why would you stop at two time axes? Why not go for three, or four, or N many?
Firstly, bitemporality is a significant increment as it allows for correcting against the past. Now you can have your immutable data cake and eat it.
Secondly, it’s helpful to see both transaction time and valid time
as the essential building blocks for creating temporal data-models.
With transaction time you achieve immutability and you have the rock
solid audit log. Should you then need an additional domain time, you
have options for modeling your data using independent facts with their
own valid time, rather than overloading multiple time fields onto a
single fact or entity.
It isn’t trivial, but with two dimensions you can model your data to reflect views of time for different business use-cases.
Conclusion
Bitemporality gives programmers more control over time. It’s useful for query, but it’s also important for the messy world that we live in, where data is moved around and we can’t guarantee strict transactional ordering.
Having two time dimensions allows us to take more advantage of the features a temporal database offers.
JUXT is releasing a new open-source bitemporal database called Crux, on April 19, 2019 at Clojure/north.


