

The world needs enlightenment
I was asked recently by a colleague - let’s call him Stathis S for anonymity’s sake… no wait, let’s call him Mr S. Sideris - how I put front-end apps together. He wanted, in particular, to understand why he should consider using re-frame for a new project. I was in a similar situation a few years ago and after reading the re-frame introduction several times I still didn’t quite get it so I went ahead without it, using just Reagent for rendering and my own code for managing all the data and state.
This worked fine at first, but we had growing pains and I found that some repetitive boilerplate code was emerging. At this point I went back to re-frame and this time it just clicked - it was the implementation we had been slowly approaching ourselves, but properly thought-out and refined.
For the things we have to learn before we can do them, we learn by doing them
- Aristotle
It’s not just about replacing our code with re-frame’s, though - re-frame changed the way I thought about the app, how it was structured and presented opportunities to make the tests better. I’ve had the good fortune to build four new apps for a client over the last three years and now would like to share the approach refined over that time which promotes simple code, comprehensive testing and ability to scale (by which I mean add features) without it becoming a big tasty bowl of spaghetti.
With whimsy as our staff and japery as our compass, let us begin.
Gimme one vision
Imagine we are building a typeahead. There are currently 614 typeahead libraries available on Github, so what we need is a single universal typeahead library to supersede them all.
A typeahead typically involves several things:
-
Local state (what the user types)
-
Data from the server (the suggestions that match what the user typed)
-
An input box on the screen for the user to type into
-
A display of suggestions on the screen for the user to select
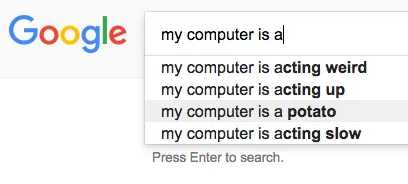
We would like the typeahead to look something like the following, prejudiced as we are by the 614 typeahead implementations we’ve seen on our journey down the infinite scroll of the internet. If we make ours look broadly similar people will already know how to use it - a design principle called familiarity, if you’re familiar with the term.
Before we get going, you’ll need the following things:
-
A Clojurescript project with Reagent, re-frame and Figwheel so we can develop with instant feedback
-
Your favorite browser all ready to fig and wheel
-
An empty washing up liquid bottle
-
A ruler
-
8 paperclips
You can use the figwheel-main template to get the first two things. The others are available on my eBay shop with discounted prices for readers of this blog post - use $DISCOUNT_CODE to get 20% off.
Isolate the view
You might think of your application being used as follows:

And you could test it like this:

There are problems here:
-
Delving into nested HTML structures to make assertions is complicated, difficult to read, prone to breaking and still doesn’t tell you if the display makes any sense to the user - a CSS class might render the whole thing invisible!
-
To make the UI display what we want we have to “drive” it with clicks and typing - very arduous to reach a deep corner case
-
It’s hard to make assertions on the photons that might hit the user’s eyeball, a complicated and mercurial API with millions of years of hacks, workarounds, new features and bugs and no decent drivers
-
If the server starts returning different data we have no way of knowing if our app will break
-
We are tempted to complect the rendering of our data with the management of it, which makes it hard to test
-
Our data can end up scattered in closed-over atoms preventing code reuse and tooling
We would like to separate the eyebally bit out and sandbox it so that it doesn’t pollute the rest of our code, which deals with pure computery data. Let’s split the UI into two parts - the data model (mmmm, fresh!) and the view (full of the sticky goo found in eyeballs) which has only one job - representing the data to the user.

The spec
The boundaries in our code are a good place to test - the model deals purely with data and is testable by normal means and the view deals purely with HTML and requires a different testing methodology. It therefore makes sense to introduce checks at the boundary between these two, where the output of the model is consumed by the view. I can define this as a spec:

Which will look something like this:
(s/def ::query (s/nilable string?))
(s/def ::loading? boolean?)
(s/def ::value string?)
(s/def ::values (s/coll-of ::value))
(s/def ::suggestions (s/nilable (s/keys :req-un [::loading?]
:opt-un [::values])))
(s/def ::component
(s/keys :req-un [::query ::suggestions]))Then I can build my model so that it outputs this data and my view so that it consumes this data.
A model

The re-frame documentation has colorful descriptions on how data flows like the water cycle. Your state of the world is used to render your app. The user, seeing the app, interacts with it and generates an event. The event is folded into the current state of the world to produce the next state of the world, which renders an updated view to the user and they can interact further. The whole cycle goes on forever, consuming events and rendering updates, growing like a black hole engulfing the universe, destabilising entire galaxies with its infinite gravity well and spewing radiation until eventually your Chrome tab runs out of memory.
For our typeahead the water cycle / black hole of death will deal with all the parts of our UI that don’t involve goo.
We can encode this flow of data using re-frame’s two main concepts - event handlers and subscriptions. If you are unfamiliar with these I suggest you first read the informative and entertaining re-frame documentation before returning here to pick up where you left off. I’ll work on some of my side projects in the meantime. Watches 2 episodes of Better Call Saul… Welcome back! Shall we begin?
We have a few events that can occur: the user types something, we ask the server for some suggestions, the response from the server arrives and the user chooses a suggestion. Every time an event happens we store some data in the database. Note that all these events, with the exception of asking the server, happen asynchronously in real life.
;; user types something (and we ask the server for some suggestions)
(re-frame/reg-event-fx
::on-query
(fn [{:keys [db]} [_ q]]
(merge
{:db (-> db
(assoc-in [:typeahead :query] q)
(assoc-in [:typeahead :suggestions] {:loading? true}))}
(if (string/blank? q)
{:dispatch [::on-suggestions []]}
{:dispatch [::server/fetch-suggestions q [::on-suggestions]]}))))
;; server responds with some suggestions
(re-frame/reg-event-db
::on-suggestions
(fn [db [_ suggestions]]
(assoc-in db [:typeahead :suggestions] {:loading? false
:suggestions suggestions})))
;; user chooses a suggestion
(re-frame/reg-event-db
::on-choose
(fn [db [_ suggestion]]
(assoc-in db [:typeahead] {:query suggestion})))Now we need a way to get the data out of our re-frame database so that our view can render it. That’s what subscriptions are for:
(re-frame/reg-sub
::suggestions
(fn [db [_ query]]
(get-in db [:typeahead :suggestions])))
(re-frame/reg-sub
::query
(fn [db [_ query]]
(get-in db [:typeahead :query])))
(re-frame/reg-sub
::typeahead
(fn []
[(re-frame/subscribe [::query])
(re-frame/subscribe [::suggestions])])
(fn [[query suggestions]]
{:query query
:suggestions suggestions}))Now that all our data eggs are in the re-frame basket it’s easy to write meaningful tests and we can benefit from other aspects like tooling (e.g. re-frame-10x), logging, dump and restore and more.
Model tests
We can use our spec to assert that, regardless of what the user types in
or what the server returns, the main ::typeahead subscription always
returns data that satisfies it.
(defn- stub-server-response [expected-request response]
(re-frame/reg-event-fx
::server/fetch-suggestions
(fn [_ [_ q callback]]
(is (= expected-request q))
{:dispatch (conj callback response)})))
(deftest querying-test
(run-test-sync
(stub-server-response "foo" ["bar"])
(let [t (re-frame/subscribe [::model/typeahead])]
(testing "user types something"
(re-frame/dispatch [::model/on-query "foo"])
(is (= {:query "foo"
:suggestions {:loading? false
:values ["bar"]}} @t))
(is (s/valid? ::spec/component @t))))))This demonstrates not only that my model code outputs data that fits the spec, but also makes a hard-to-test asynchronous call to the server behave synchronously using the stub. This is a feature of day8/re-frame-test and is really useful in making complicated models easily testable. It also lets me test the transient state of the data being requested but no response received:
(deftest loading-suggestions-test
(run-test-sync
(re-frame/reg-event-fx
::server/fetch-suggestions
(fn [_ [_ q callback]]
(is (= "foo" q))
;; do not dispatch callback in order to observe the state before the server has returned a response
{}))
(let [t (re-frame/subscribe [::model/typeahead])]
(testing "user types something"
(re-frame/dispatch [::model/on-query "foo"])
(is (= {:query "foo"
:suggestions {:loading? true}} @t))
(is (s/valid? ::spec/component @t))))))Tests don’t need to run asynchronously with complicated locking or suffer from race conditions because with re-frame we’ve separated the what from the when. Now we have covered the following parts in testing:

The goo
The view is where our data meets a random load of HTML which will hopefully present the data in a way that makes sense to the user. The best way of testing that is to just render something and have a look at it! Let’s write some Reagent code to manifest our vision in html tag form:
(defn- suggestions [{:keys [loading? values] :as any?}]
(when any?
[:div.suggestions
(if loading?
[:div.loading "Loading suggestions..."]
(if (seq values)
[:ul
(map-indexed
(fn [i v]
[:li {:key (str i v)
:on-click #(re-frame/dispatch [::model/on-choose v])} v])
values)]
"No suggestions found, please try another search"))]))
(defn typeahead-component [model]
[:div.typeahead
[:input {:type "text"
:value (:query model)
:placeholder "Start typing to see suggestions"
:on-change #(re-frame/dispatch [::model/on-query (.. % -target -value)])}]
[suggestions (:suggestions model)]])
(s/fdef typeahead-component
:args (s/cat :model ::spec/component))
(defn typeahead []
(let [model (re-frame/subscribe [::model/typeahead])]
(fn []
[typeahead-component @model])))Notice how simple it is - no changing of the data as it gets passed around, just pure transforming functions to represent the data directly in HTML.
View tests
I use devcards to exercise the view code, and for assertions I use my gooey eyes. Devcards makes this practical because it allows me to render many permutations of data, so that I can build a screen showing all my visual edge cases in one go. I know I am using realistic data in these cards because I can check it against my spec, and I can ensure this by turning on instrumentation so that it will blow up if my test data drifts from the spec.
(defn- typeahead* [m]
(if (s/valid? ::spec/component m)
[typeahead-component m]
[:div.error
[:h4 "Bad input"]
[:pre [:code (s/explain-str ::spec/component m)]]]))
(defcard-rg typeahead
[:div
[:h1 [:i "Initial state"]]
[typeahead* {:query nil
:suggestions nil}]
[:h1 [:i "Loading suggestions"]]
[typeahead* {:query "my computer is a"
:suggestions {:loading? true}}]
[:h1 [:i "Some suggestions"]]
[typeahead* {:query "my computer is a"
:suggestions {:loading? false
:values ["My computer is acting weird" "My computer is a potato"]}}]
[:h1 [:i "No suggestions"]]
[typeahead* {:query "bz"
:suggestions {:loading? false
:values []}}]])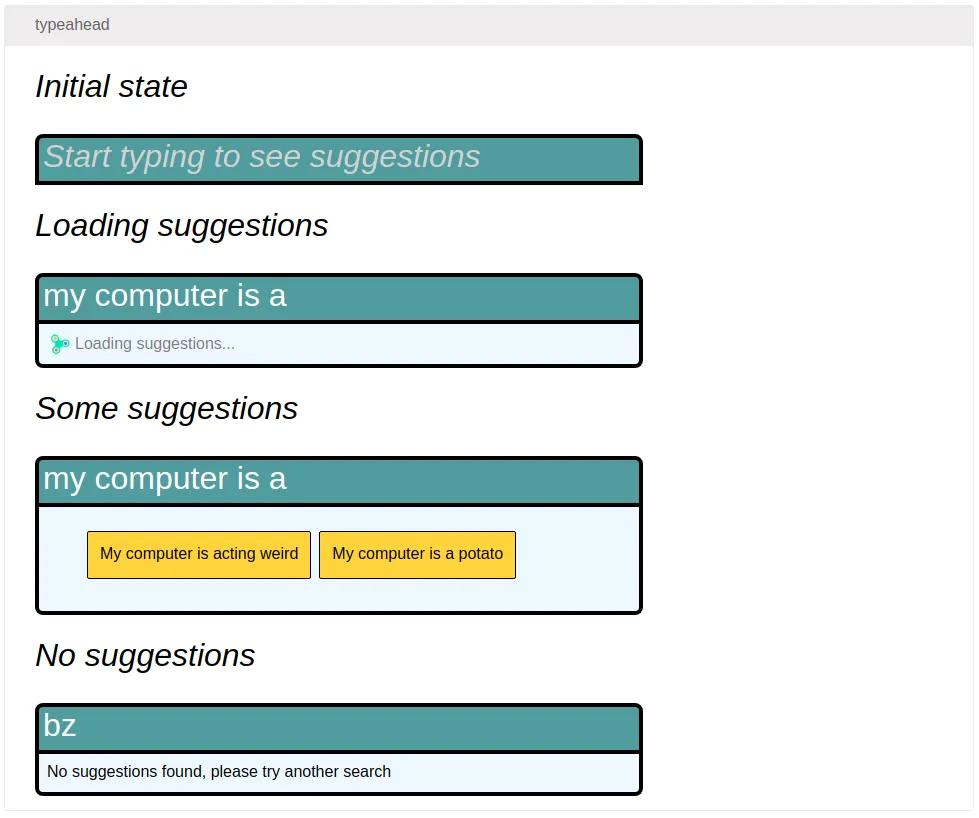
I can now go one step further and try to render randomly generated data using the spec:
(defcard-rg generated-typeahead
(let [models (gen/sample (s/gen ::spec/component))]
[:div
(map-indexed (fn [i m]
[:div {:key i}
[:pre (pr-str m)]
[typeahead* m]])
models)]))I quickly found that I had React problems with duplicate keys if the same suggestion appeared multiple times. It also forced me to consider what to do if a suggestion was an empty string, because that looks really weird:
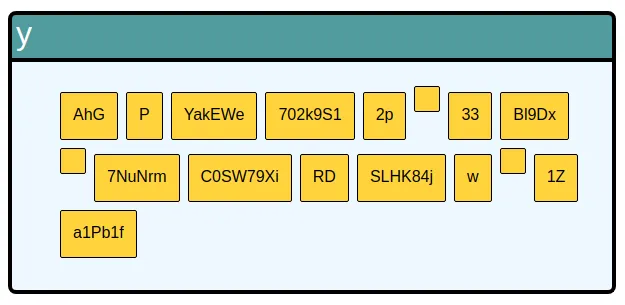
With some fixes in place for that, I now know that
-
my model always outputs data conforming to my spec
-
my view can properly display any data that conforms to the spec

Automatic for the people
Reviewing devcards by eye before a release isn’t too onerous, but it’s still easy to forget and then harder still to track down which change broke the UI. Automating this step is the natural way to go, and with a combination of chrome headless and imagemagick it’s possible to capture screenshots and diff devcards against reference versions. I have written a library to do this called kamera, which I introduce in my next post here.

998… 999…
The final pieces of the puzzle are at the server/model boundary. If we knew what sort of data the server might return then we could prove our model can handle it, and if our model can handle it we know our UI can display it.
Some API technologies are self-describing - among them GraphQL and Swagger (OpenAPI). I have written data generation libraries for both of these: lacinia-gen and martian-test respectively, allowing you to generate data that your server will return as an input to your model tests.
We now know that
-
Whatever data our server generates (or the user provides), our model can accept as input
-
Whatever its input, our model can output data conforming to the spec
-
If the data conforms to the spec, our view code can display it correctly
The transitive property of our tests proves that we can render everything properly, our application works as expected and we can add “full stack testing” to our CV.

As a bonus, we also know that:
-
If the server API changes we can run our model tests to find out if we need to make changes
-
If we do need to change our model code we won’t need to touch the view code
-
If we just want to change how some data is represented we only need to change the view code
Ahh, the bonus, the deep bonus. I don’t know if you heard me counting, I did over a thousand.
Conclusion
With some separation of concerns, introduction of code boundaries and assertions made at each boundary we can improve the way we build and test our apps. Our model is simple because its one job is managing how events alter our state and delivering that data to the view, and our view is simple because its one job is representing that data in HTML. It’s a bit like how a ship is built - each compartment is watertight and small enough that if any one of them is breached it can be sealed off to stop the ship sinking.
On that rather apt metaphor for software development, I’ll just recap on the libraries and tools used:
-
Model it: re-frame, re-frame-test
-
Gen it: martian (blog post), lacinia-gen (blog post)
-
Reload it - figwheel-main template
-
Visualise it - kamera
The code examples are from a toy project called re-partee that I created to demonstrate the principles in this blog post.


